Tonic by Canopy
Reimagining personalized content recommendations for the privacy age.
Founded by Brian Whitman and a team of ex-Spotify employees, Canopy has developed a recommendation engine that uses on-device machine learning and differential privacy to deliver personalized content recommendations without collecting or storing any personal data. Through our research-led process, we collaborated closely with Canopy's product team to concept and design the first app built on this technology — launching, testing, and iterating with a growing group of Beta users until the app was released publicly, as Tonic.
Type/Code’s qualitative and quantitative research drove the product strategy by defining the problem to be solved and the target market for whom to solve it. By generating and evaluating design solutions with real users we were able to identify and highlight the app’s unique value proposition - a zero-onboarding experience that provided fresh but relevant content recommendations each day, without adding to the noise or exacerbating the bad tech hygiene to which the current digital landscape has made us all complicit. Our unique and effective user interface brought the brand to life, providing transparency without being overly technical (a pitfall we discovered only re-ignites users’ concerns and invites skepticism) and humanizing the experience through a unique editorial voice. Throughout the product release cycle we utilized valuable user testing and survey feedback to continually grow and evolve the product, ensuring the greatest impact on Tonic’s public launch.
Defining the Problem to be Solved
Before we could design Canopy's first app, we needed to define the problem that it would solve. Through our research process, we conducted a combination of interviews and surveys and formed a clear picture of our target audience — their behaviors and attitudes towards content recommendations, algorithms, and data privacy — that would inform how to productize this revolutionary technology.

Most of the people we talked to during our research process get their content recommendations through social media. But the endless glut of content is taking its toll, and many are beginning to question its effects on themselves, their health, and society.
Plagued with predictable suggestions, opaque controls, and clickbaity titles, algorithmically recommended content can range from "terrible" to just "pretty good." Even good recommendations start to suffer when there is no element of surprise or unpredictability.
What we heard was not only a growing discontent over the amount of data that is collected, but also a sense of powerlessness over how that data is being used. For some, this has led to a sense of apathy for some, and for others, concern.
Whether concerned or apathetic, we learned that most people are now taking some steps to protect their data. But, outside of a few design patterns established the big players like Google and Facebook, there is no clear template for what data privacy looks like. Most of the people we surveyed confessed that they don’t actually know how to protect their private data, and feel that nothing they can do will make much of a difference anyway.

Generating and Validating Design Solutions
Using what we learned from our research, we began ideating on the product design. With Canopy's engineering team focusing on how the technology would work on the back-end, our job was to imagine all the ways a private recommendation engine could work in the user’s hands. We tested rough concepts to gather reactions and validate our ideas.
Although people were initially skeptical of the technology, the concept for a bite-sized, thematically-curated, daily mix of content resonated with those for whom the endless scroll was becoming a daily grind, so we focused on simplicity and putting the content first, forgoing the technical explanations and radical transparency that we'd initially thought would be our key differentiators.
Once our concept had been established, we began architecting the user experience of the app in its entirety. Using wireframes, we defined the app’s information architecture, navigation, content, and interactivity.
Designing the Interface
Designing a product that forgoes the current value exchange gave us the unique opportunity to rethink some established design patterns. With an underlying theme of "designing a better internet", we leaned into Canopy's warm and friendly aesthetic. While powerful technology was driving this new recommendation engine, the experience needed to highlight the human side of connecting people with great content.
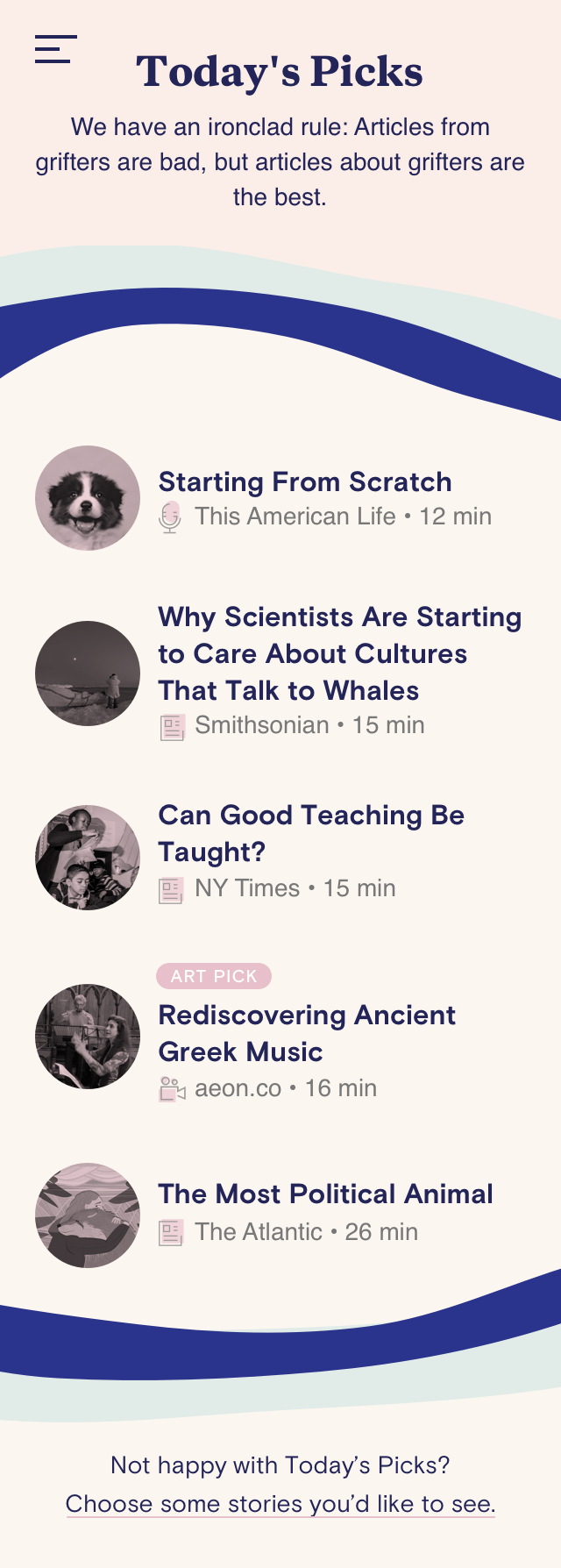
Zero Accounts
Users don't even need to sign in to use Tonic. Nothing is public and none of the user's raw data is collected or stored.Editorial Voice
Thematic curation and a point-of-view are critical in allowing Tonic to recommend a variety of content without feeling random.Branding
Our UI embraced the organic shapes and soft palettes of Canopy’s branding. The Canopy logo became the metaphor for a private space that is personalized to the user and free from outside influences.Quality over quantity
No scrolling through endless feeds. Tonic offers only a handful of selections each day, thoughtfully curated by a human and delivered by a recommendation engine.Context
Providing other bits of context allowed us to recommend things somewhat outside of the user’s comfort zone and offer an element of surprise.Positive Feedback Signal
To avoid a content rut we offered users a way to steer their recommendations and offer the algorithm new positive feedback signals, without overwhelming them with a ton of content.Iterative Product Design
Our design team worked as an extension of Canopy’s product team. Throughout the Beta program, we continued to concept, evaluate, prototype, and test new ideas and solutions as part of an iterative product release cycle until we found the right product-market fit.
 A content-first onboarding flow lets users share specific positive signals rather than vague category interests.
A content-first onboarding flow lets users share specific positive signals rather than vague category interests.
Our onboarding process was designed to emphasize content over preferences, relieving users of the mental exercise of having to choose which topics they like and allowing them instead to be immediately immersed in interesting articles, building their own first playlist of content, which would then inform future recommendations.
Our Beta users loved the fleeting selection of content they received each day, but they didn’t want to miss out. One of the first features we added was a notification setting that allowed them to set a daily reminder at the time of their choosing. Whether they were a morning rush-hour reader or a late-night podcast listener, they wouldn’t miss out on their daily picks.
 1. The idea was to hand over control to the users themselves.
1. The idea was to hand over control to the users themselves.
 2. By interacting with their activity, they could ignore read articles.
2. By interacting with their activity, they could ignore read articles.
 3. Or go back and check their reading details.
3. Or go back and check their reading details.
 4. Thus your picks are truly personalized to you.
4. Thus your picks are truly personalized to you.
Although our early iterations taught us not to lean too heavily on explaining the technology, we still wanted to offer some transparency into how the recommendation engine works and give users a sense of control that went beyond the usual, ineffective mechanisms. Through ideating, prototyping, and testing we explored a variety of concepts that lets users see how their past activity informs their future recommendations, and gives them the ability to adjust it.
From Idea to Beta to Launch
Our Beta users provided invaluable feedback through surveys and user tests, helping us to design and refine the product the world now knows as Tonic. With our iterative research-lead design process, we were able to help Canopy launch a product that resonates with users, while confidentially deviating from common product patterns for the sake of a delightful privacy-focused experience.
In 2020, Canopy was acquired by CNN, who planned to use its technology to power its news aggregation service.
Healthline Media →
Jobs for the Future